Parallel Computing
An Overview of Parallel Computing Methods
Parallel computing lies at the heart of High-Performance Computing (HPC), enabling tasks to be distributed across multiple processors for simultaneous execution. Before diving into this material, ensure you’ve reviewed all prior Using the HPC Systems sections.
Understanding Parallelisation Paradigms
To use parallel computing effectively, it’s vital to identify the parallelisation strategy your program employs. Without this understanding, selecting the correct computational options becomes difficult. This process can sometimes be tricky but is essential for optimising performance.
Types of Parallelisation:
Embarrassingly Parallel Tasks: Fully independent processes – use job arrays for these.
Multiprocessing or Multithreading(OpenMP): Leverage shared memory parallelism.
Message Passing (MPI): Use options for MPI parallelism.
GPU Computing: Use options for GPU-specific configurations.
Important
Remember, scaling has its limits. Always monitor resource usage to confirm your jobs are effectively
utilising what you’ve requested (e.g., via seff JOBID).
For scaling advice, consult our IT Services’ Research and Innovation team early in your workflow.
Core Models of Parallel Programming
Parallel programming enables simultaneous execution of instructions across multiple processors. Many users rely on pre-built parallel features within software, so creating parallel programs isn’t always necessary. However, understanding the different parallel programming approaches is crucial when running or optimising jobs.
1. Embarrassingly Parallel
Frequently used for tasks requiring the same program to be run repeatedly with different datasets or parameters.

Job Arrays: SLURM provides an easy way to handle large batches of such tasks. Any program can be run this way if the problem can be divided into independent tasks. Each job in an array is assigned a unique identifier.
Resource Allocation: Specify resources for a single job and define the total number of jobs in the array.
Use Cases: Parameter sweeps, independent data processing tasks.
See: Embarrassingly Parallel .
2. Shared Memory Parallelism
This model uses multiple threads or processes that share access to the same system memory, all running on a single machine.
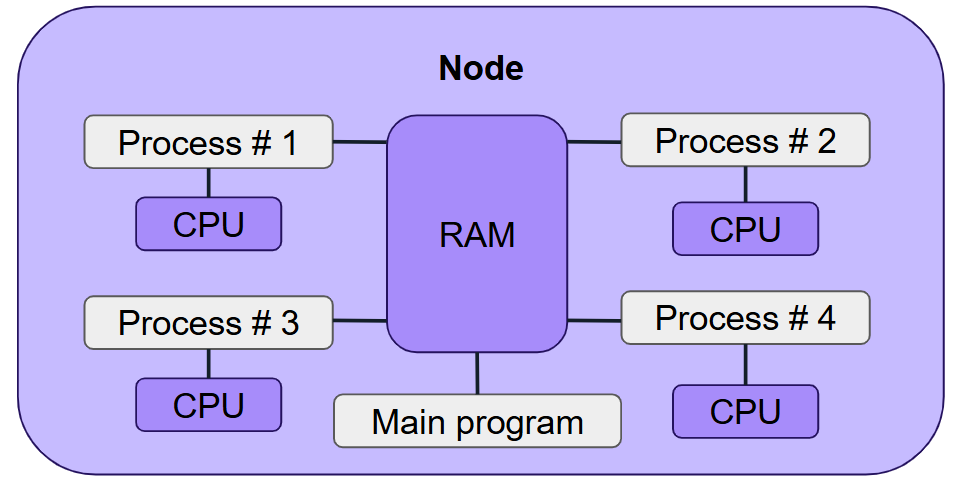
Resource Allocation: Request a single node, one task, and multiple CPUs.
- Examples:
MATLAB (internal parallelisation & parallel pool).
R (built-in parallel library).
Python (e.g., NumPy, threading, multiprocessing).
OpenMP, BLAS, FFTW, and other libraries.
3. MPI (Message Passing Interface) Parallelism
MPI facilitates communication between tasks working together on different parts of the same program.
Tasks communicate via high-speed interconnects between nodes. MPI is essential for large-scale scientific applications and can handle thousands of CPU cores. MPI programs are typically tailored to specific scientific challenges.
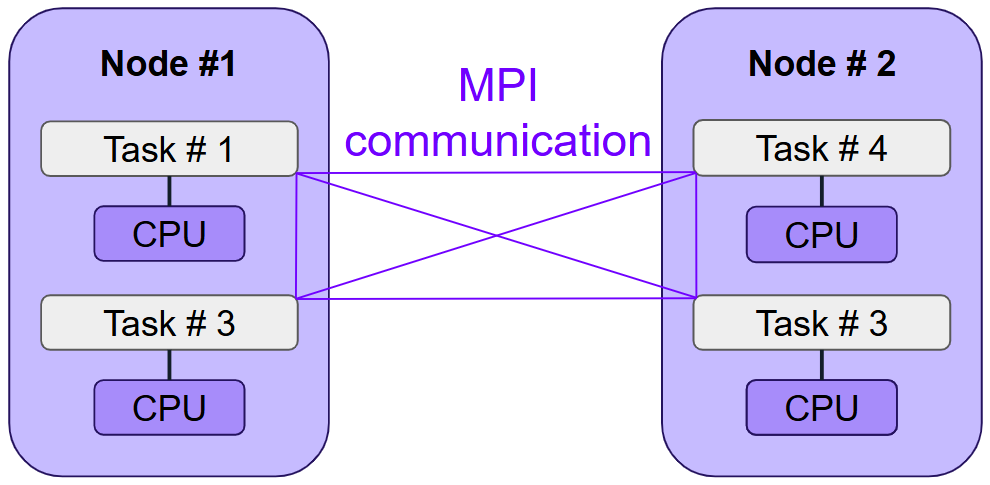
Resource Allocation: Request one or more nodes with multiple tasks but avoid assigning multiple CPUs per task.
Use Cases: CP2K, LAMMPS, OpenFOAM.
See: MPI Parallelism.
4. GPU Parallelism
GPU parallelisation employs specialised hardware (GPGPUs) with thousands of processing cores to execute calculations faster than CPUs.
GPUs are ideal for numerical calculations but require specific programming. Most GPU-accelerated programs split tasks between the CPU (e.g., I/O operations) and GPU (e.g., computations). GPUs cannot be utilised by generic CPU programs unless designed explicitly for GPU acceleration.
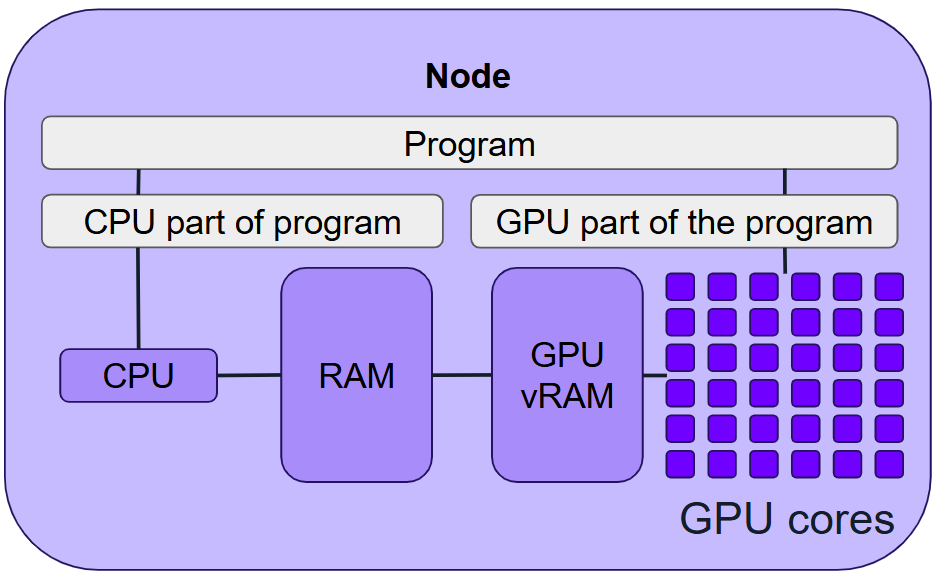
Resource Allocation: Request a single node, a single task, optional multiple CPUs, and one or more GPUs.
Examples: Machine learning frameworks (TensorFlow, PyTorch).
See: GPU Computing.
Can My Code Run in Parallel?
Standard serial code won’t run in parallel without modification. As a user, it’s essential to understand whether your code supports parallel execution and, if so, which model it follows.
When deciding whether to use parallelisation, consider these principles:
Amdahl’s Law: The maximum speed-up is limited by the serial portion of the program.
Gustafson’s Law: Larger problems benefit more from parallelisation.
If most of your program’s work is serial, parallelising may provide little benefit. Before committing to large runs, benchmark your program with varying CPU core counts to determine its scalability.
Combining Parallelisation Models
Some advanced workflows require combining different parallelisation approaches. Below are examples of such combinations:
Embarrassingly Parallel Everything Any task can be executed in an embarrassingly parallel manner, including shared memory, MPI, or GPU jobs. Each job runs independently with its own resources.
Hybrid Parallelisation Combining MPI and shared memory models. Programs that utilise this model can require both multiple tasks and multiple CPUs per task.
Example: Hybrid CP2K configurations (e.g., psmp) use both methods, whereas standard MPI versions (e.g., popt) do not.
The optimal balance of MPI tasks and CPUs per task should be determined through testing.
Shared Memory with GPUs GPUs are highly efficient for calculations, while multiple CPUs handle preprocessing to minimise idle GPU time.
Common in machine learning frameworks like TensorFlow and PyTorch.
Multi-Node Without MPI Some programs can parallelise across nodes without using MPI for communication.
These setups often require custom scripts and depend on the software.
Getting help
We are here to support you with any aspect of parallel computing. If you require further support or need specific advice, please contact IT Services’ Research and Innovation team or if you have more specific queries about programming / coding for HPC clusters e.g. CUDA programming please contact the Research Software Engineering team.
This material contains material adapted from Aalto Scientific Computing Documentation, licensed under CC BY 4.0 Changes were made to the original content.