MPI for Multi-node and Parallel Jobs
Overview
Confirm that your application is built to support MPI.
Compile your code using MPI-aware compilers. Be sure to load the same modules in your job script.
To assign multiple tasks on a single machine, use
--nodes=1and--ntasks=n.Launch the program using
srunif you’re relying on system-installed MPI modules, or usempirunfor custom-built MPI.To distribute tasks evenly across multiple machines, combine
--nodes=Nwith--ntasks-per-node=nto yield a total of N x n tasks.Always check resource usage with tools like
seff JOBIDto ensure efficient use of allocations.If you are uncertain about scaling up, contact the IT Services’ Research and Innovation team at an early stage.
MPI allows a program to run concurrently across many cluster nodes, although it typically requires more specialised programming.
What is MPI?
The Message Passing Interface is a standard for passing data and other messages between running processes which may or may not be on a single computer. It is commonly used on computer clusters as a means by which a set of related processes can work together in parallel on one or more tasks. These strands (processes) must therefore communicate data and other information by passing messages between each other.
MPI is used on systems ranging from a few interconnected Raspberry Pi’s through to the UK’s national supercomputer, Archer.
MPI Implementations
The Message Passing Interface (MPI) itself is just a specification for a message passing library.
There are multiple implementations of this specification, each produced by a different organisation, including OpenMPI and Intel MPI. This documentation includes information on the MPI implementations available on Stanage. On the Stanage cluster these implementations have been compiled in a way that allows them to make optimal use of the high-speed network infrastructure (OmniPath). If you are not sure which implementation to use then try the latest available version of OpenMPI.
Batch MPI
To use MPI you need use module load to activate a particular MPI implementation
(or module load an application that itself loads an MPI implementation behind the scenes).
Here is an example that requests 4 slots (CPU cores) with 8GB of RAM per slot then runs a program called executable
in the current directory using the OpenMPI library (version 4.1.4, built using version 12.2.0 of the gcc compiler).
It is assumed that executable was previously compiled using that exact same MPI library.
#!/bin/bash
# Request one node
#SBATCH --nodes=1
# Request 4 cores per node
#SBATCH ntasks=4
# Request 8GB of RAM per node
#SBATCH mem=8G
# Load a MPI library
module load OpenMPI/4.1.4-GCC-12.2.0
# Run a program previously compiled using that specific MPI library
srun --export=ALL ./executable
Unlike shared memory models, MPI requires programs to explicitly send and receive data between tasks. Most applications must be written with MPI support from the outset, so standard serial code won’t benefit from MPI unless rewritten accordingly.
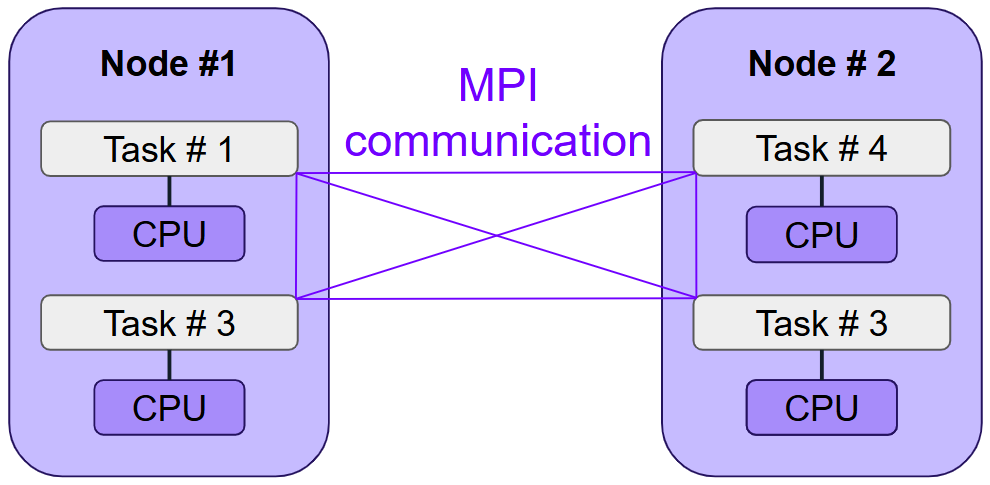
MPI programs usually follow this pattern:
The same executable is launched in several separate processes.
All processes connect to one another through MPI.
Each process is assigned a unique identifier called a “rank”.
Each rank performs a specific portion of the work. Rank 0 often handles I/O and status messages.
The MPI environment is closed after execution ends.
If you’re using MPI modules provided by the system, Slurm communicates rank and task details using a library called PMIx. This may not work seamlessly with external MPI builds.
Building and Executing MPI Programs
Compiling with MPI
Choose an MPI implementation for building your application. Several are available, all conforming to the MPI standard. We suggest using the latest version of OpenMPI for compatibility with the cluster environment. For information on other installed versions, see Parallel Systems on Stanage.
Requesting MPI Resources in Slurm
To allocate resources for an MPI job, the typical format is: --nodes=1 --ntasks=N.
This ensures all MPI tasks run on a single machine—ideal for communication-intensive programs.
When scaling to multiple nodes, use: --nodes=N --ntasks-per-node=n. This launches N x n tasks,
balancing them across machines. Each task gets 1 CPU by default. To increase this (if your programme supports it), see the section on
hybrid parallel models.
Example: MPI Program to Estimate Pi
We’ll use the pi-mpi.c example, which estimates π using a Monte Carlo method, and supports multiple MPI tasks.
Start by compiling with the MPI module:
module load hpc-examples
module load OpenMPI
mpicc -o pi-mpi ${HPC_EXAMPLES}/slurm/pi-mpi.c
Run interactively:
srun --nodes=1 --ntasks=2 --time=00:10:00 --mem=500M ./pi-mpi 1000000
Or via a Slurm script (pi-mpi.sh):
#!/bin/bash
#SBATCH --time=00:10:00
#SBATCH --mem=500M
#SBATCH --output=pi-mpi.out
#SBATCH --nodes=1
#SBATCH --ntasks=2
module load OpenMPI
srun --export=ALL ./pi-mpi 1000000
Submit with:
sbatch pi-mpi.sh
You can inspect the output file using cat:
$ cat pi-mpi.out
node032.pri.stanage.alces.network: This is rank 1 doing 500000 trials
Calculating pi using 1000000 stochastic trials
node032.pri.stanage.alces.network: This is rank 0 doing 500000 trials
Throws: 785491 / 1000000 Pi: 3.141964
Important
Here we didn’t specify an OpenMPI version, so the system default was used. However, for reproducibility and to avoid runtime errors, always load the same version of OpenMPI as you used when compiling the program. Mismatched major versions (e.g. 3.x vs 4.x) can cause MPI initialisation errors or crashes, and even minor differences can affect runtime behaviour.
Special Cases and Tips
Ranks Not Detected
When using MPI libraries outside the system default, ranks may not be recognised automatically. Add the following to your job script if needed:
export SLURM_MPI_TYPE=pmix_v2
Note: We suggest pmix_v2 here for broad compatibility with different MPI builds, but newer MPI libraries may also support pmix_v4.
Performance Monitoring
The seff script can be used as follows with the job’s ID to give summary of important job info :
$ seff job-id
For example, on the Stanage cluster:
$ seff 64626
Job ID: 64626
Cluster: stanage.alces.network
User/Group: a_user/clusterusers
State: COMPLETED (exit code 0)
Nodes: 2
Cores per node: 1
CPU Utilized: 00:02:37
CPU Efficiency: 35.68% of 00:07:20 core-walltime
Job Wall-clock time: 00:03:40
Memory Utilized: 137.64 MB (estimated maximum)
Memory Efficiency: 1.71% of 7.84 GB (3.92 GB/core)
You can also monitor individual job steps by calling seff with the syntax seff job-id.job-step.
If your CPU usage is consistently low, your code may not be making effective use of the available resources — this could be due to inefficient code or a lack of parallelisation.
If memory usage is far below or above the requested amount, consider adjusting your allocation. It’s generally best to request slightly more RAM than your code typically uses, to avoid job failures while minimising waste.
Exercises
Exercise 3: Can Your Code Use MPI?
Look at your code’s documentation or output. Keywords that hint at MPI support include:
MPI
mpirun
mpiexec
distributed
rank
Exercise 4:
Explore our documentation pages on parallel implementations on Stanage. Pay attention to examples, best practices, and cluster-specific tweaks - they’ll give you a head start in deploying MPI effectively on our systems.
MPI Training
Training courses from the national supercomputing centre are available here
What’s Next?
The next guide introduces GPU parallelism and how to use GPUs on the cluster.
This material contains material adapted from Aalto Scientific Computing Documentation, licensed under CC BY 4.0 Changes were made to the original content.