Attention
The ShARC HPC cluster was decommissioned on the 30th of November 2023 at 17:00. It is no longer possible for users to access that cluster.
Jupyter and JupyterHub
Introduction
Jupyter Notebooks are executable documents containing: formatted text, formatted maths, chunks of code plus figures, tables and textual output generated by that code.
Notebooks can be used:
to develop and execute linear data analysis workflows;
to present linear workflows to others;
as runnable documentation for software packages (e.g. NetworkX examples);
as executable teaching materials (e.g. BAD days tutorials);
Jupyter itself is web application that interprets, runs and renders Notebooks. You interact with it by As you interact with it by just connecting from your web browser the Jupyter server software can be running on your local machine or a remote server (which may have more memory, CPU cores and/or GPUs than your local machine).
On the University’s ShARC cluster a JupyterHub service allows a user to:
Log in to the JupyterHub web inteface,
Specify what resources (memory, CPU cores, GPUs) they want for a Jupyter session,
Start and run a Jupyter Notebook server on a worker node in the cluster using these resources.

Using Jupyter on ShARC
- 1. Connecting to JupyterHub, requesting resources (RAM, processors, GPUs) for your Jupyter session, and starting your session
- 2. JupyterLab interface
- 3. Terminal in your browser
- 4. Programming languages, software packages and execution environments
- 5. Creating, editing and running Jupyter Notebooks
- 6. Monitoring and controlling your Jupyter session
- 7. Errors and troubleshooting
Maintenance of ShARC’s JupyterHub service
The server that provider the JupyterHub service is typically rebooted at 03:26 on the 2nd Tuesday of the month to install security updates.
JupyterHub on a Grid Engine cluster: internal workings
The hub of JupyterHub has several components:
an authenticator that allows users to log in, possibly using externally-stored identity information;
a database of user and state information;
a spawner that can start single-user Jupyter Notebook servers on demand.
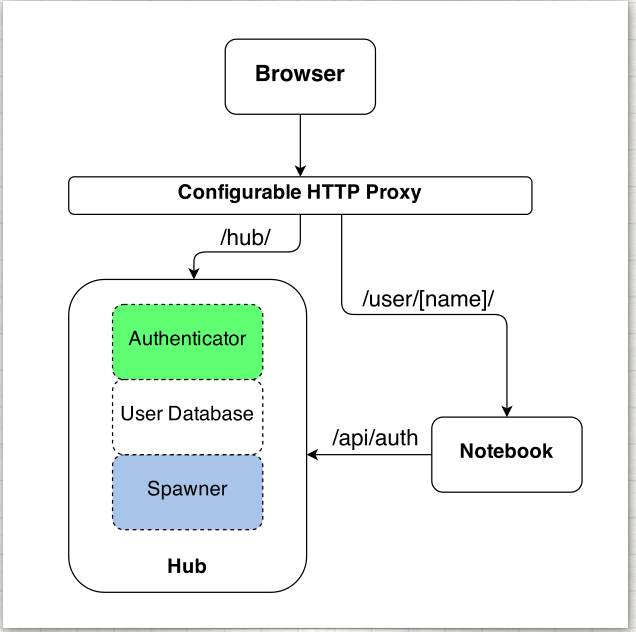
There is also a web proxy that first routes web connections from a given user to the hub for authentication and possibly choosing spawner options then, after a single-user Jupyter server has been spawned, certain web connections are forwarded to the Jupyter Notebook server. From the user’s perspective it appears that they are interacting with a single web application, even though at times they might be talking to a single-user Jupyter server that running on a different machine to the Hub.
ShARC uses BatchSpawner to spawn single-user Jupyter servers on one or more worker nodes on ShARC by submitting batch jobs to the Grid Engine job scheduler.
The JupyterHub and BatchSpawner configuration allows the user to specify the Grid Engine resources required for the Jupyter session in advance via a web form then these resources are requested as part of the batch job submission.
Credits
The JupyterHub service on ShARC was originally developed and maintained by the University’s Research Software Engineering team, funded by OpenDreamKit, a Horizon2020 European Research Infrastructure project (676541) that aimed to advance the open source computational mathematics ecosystem.