What is High Performance Computing?
Introduction
If you are new to high-performance computing your first question is most likely: “What is high-performance computing (HPC)?”

The old Iceberg system server racks.
A good definition is:
High Performance Computing most generally refers to the practice of aggregating computing power/resources in a way that delivers much higher performance / resource than one could get out of a typical desktop computer.
In practice, the term “HPC” is difficult to define well in one concise and simple definition due to the varied characteristics of the many software and hardware combinations which constitutes HPC.
It should also be noted that HPC is usually used to mean either “high performance computing” or “high performance computer” which is usually clear from the context of its use.
Users of high performance computing will typically dispatch their workloads to a HPC cluster which is a large computer aggregrated from many smaller computers. It should be noted however that using a HPC cluster is not the only way run these kinds of workloads as other platforms can be used, e.g. dedicated high performance workstations.
Who can use or should use a HPC cluster?
Typically a researcher’s local desktop or laptop has between 8 to 16 GB of memory, 4 to 16 CPU cores and a few TB of disk space where HPC clusters will usually have at least an order of magnitude more resources, if not more. Their research workloads may be too large for their own machine due to not having enough memory, disk space or it may simply take too long to run computations in a timely manner.
The thought of using a HPC cluster might seem intimidating to researchers, but in principle any researcher with a workload that is too large for their desktop or laptop should access HPC resources and can do so via a small amount of HPC training. This is all provided free of charge at the University of Sheffield for University of Sheffield academics by IT Services.
What is a HPC cluster?
A HPC cluster is a large computer composed of a collection of many smaller separate servers (computers) which are called nodes. Nodes are typically connected to one another with a fast interconnect, such as Omnipath on the Stanage cluster, in order to pass data in between them very quickly.
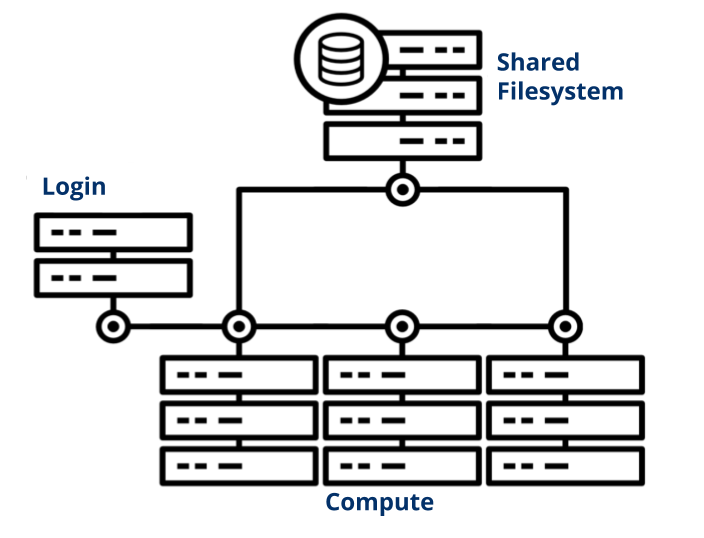
A general cluster schematic, source: Yale Center for Research Computing
Both general HPC clusters and those at Sheffield are composed of:
login nodes (also known as headnodes) where users login, edit, upload / download files but should not run any intensive programs and cannot load software modules.
compute nodes where user jobs are ran.
large memory nodes which are compute nodes with increased amounts of RAM available.
GPU nodes which are compute nodes with multiple GPUs available.
reserved nodes which are typically purchased by a department or research group for their exclusive use.
storage nodes / the attached filestores which provide the cluster storage areas.
All cluster nodes are equipped with the same types of components as a consumer laptop or desktop, i.e. CPU cores, memory and disk space but differ as these components are drastically improved in terms of quantity, quality, redundancy and magnitude of compute power.
All user work is dispatched to a cluster using a tool called a job scheduler. A job scheduler is a tool used to manage, submit and fairly queue users’ jobs in the shared environment of a HPC cluster. A cluster will normally use a single scheduler and allow a user to request either an immediate interactive job, or a queued batch job.
Login nodes
The login nodes are your gateway to the cluster from which you view/edit/upload files and dispatch jobs to the compute nodes. These nodes will be accessible over SSH however running any intensive programs is forbidden and cluster software is not available for this reason.
Compute nodes
The compute nodes are where your jobs will run. The compute nodes mount all shared filesystems making software and files available for your jobs irrespective of the node/s in which they run. These nodes are not accessible over SSH and direct access via methods other than the scheduler is forbidden.
Large memory nodes
Large memory nodes are identical to normal compute nodes but have additional memory capacity. Thus, they have the capability to run more memory-intensive shared memory parallel processing (OpenMP) jobs. Jobs requiring sufficiently large amounts of RAM will automatically be dispatched to these nodes.
GPU nodes
GPU nodes are principally the same as compute nodes but with the addition of special compute optimised GPUs typically used for accelerating modelling of engineering applications of AI / machine learning tasks. Jobs requiring the use of GPUs must specify this requirement as part of their resource request.
When should I use HPC?
You should use HPC resources when your research workflows stand to benefit from HPC or where a research workflow is not possible to run on your own available resources.
The following are typical use cases when it may be beneficial to request access to a HPC cluster:
Computations need much more memory than what is available on your computer.
The same program needs to be run many times (usually on different input data).
The program that you use takes too long to run, but it can be run faster in parallel with multiple cores, typically utilising MPI or shared memory parallel processing (OpenMP).
You need access to a GPU (your program needs to be written in a way that allows it to use your GPU or it uses GPU acceleration).
When should I not use HPC?
Working with sensitive data
Danger
The High Performance Computing service must not be used to store or process any restricted or sensitive data.
Examples of restricted or sensitive data include medical records, personal information, financial data, commercially sensitive data etc…
If you are unsure whether you are working with restricted or sensitive data, do not transfer data to the HPC clusters without first discussing your requirements with IT Services.
Due to the complexity of the multi-user High Performance Computing service, the service is not currently certified as being compliant with the Cyber Essentials, Cyber Essentials Plus or ISO 27001 schemes/standards. This is unlikely to change in future.
Extra care should always be taken when dealing with sensitive information; if you are in any doubt about the sensitivity of information, or how it should be handled, then please contact IT Services research-it@sheffield.ac.uk for advice.
Hint
If processing of restricted or sensitive data is required, we recommend use of the Secure Data Service and getting in contact with the Secure Data Service team
Low volume workloads
Learning to use the HPC clusters will take both time, training and effort. If you have a low volume of work then investing time in learning to use Linux, shell scripting and other skills for using HPC clusters may be better spent elsewhere.
Low volume, low memory serial workloads
Using a HPC cluster is not a magic bullet that will make any workload run faster. Any workflows that only run on a single core (serial processing) and do not need large amounts of memory are likely to run slower on the HPC than on most modern desktops and laptop computers.
If you run a low volume of serial jobs you will likely find your own computer would have completed these quicker.
For training purposes
University HPC clusters are used to facilitate large computational workloads and are not usually used as a training aid / facility. Exceptions may be made for HPC specific training with prior engagement with the HPC staff.
HPC staff can help you optimise your workflows and software for use on the HPC clusters, but they cannot teach you how to use your program in great detail nor train you on the basic usage of a program.
At The University of Sheffield, research training needs should be addressed via training courses provided by IT Services’ Research and Innovation team (VPN must be turned on), Research Software Engineering or Departmental / research group resources. PhD students can also make use of their doctoral development program to attend specific courses from any department that are relevant to their PhD training and development.
For non-legitimate or non-research purposes
University HPC clusters are provided to facilitate legitimate research workloads. Inappropriate usage of cluster resources, e.g. mining crypto-currency, hosting web services, abusing file storage for personal files, accessing files or software to which a user is not entitled or other non-legitimate usage will likely result in an investigation under the host organisation’s IT Code of Practice.
Account sharing is also not permitted and any users/parties caught sharing accounts will also likely result in an investigation under the host organisation’s IT Code of Practice.
The University of Sheffield IT Code of Practice can be found at the following link: https://www.sheffield.ac.uk/it-services/codeofpractice/core
How do I get started?
Potential users should first register and attend training courses RIT 101 and RIT 102 on IT Services’ Research and Innovation course details and registration information website (VPN must be turned on) and should then request an account.